













Scientific Process
Recently, RopeLab was approached by a student asking for help in carrying out some tests for his year 10 school science project. Tim had a good idea and we agreed to help. Watching his process and reading his report prompted us to think through some of the scientific processes that we use as a way to nut out problems. While we like to rely on science to give us answers, it is important that we have the ability to assess information critically and draw reliable results.
It starts with being inquisitive. We observe, wonder, or question something. We do this regularly and the ever evolving field of ropes gives us plenty of food for thought. Observations can be collected and organised for some interesting results such as the type we gather from surveys. However, results can be influenced by many different variables so to dig deeper into a topic, we may extend our observations to test systems under controlled conditions and gather empirical data. Tim’s application of formal experimental design is described below.
First, we need to narrow down our interest. We use our observations and gathered knowledge to formulate a hypothesis. The hypothesis is a general statement describing our best guess. This must be a falsifiable statement, meaning experiments may support or refute it. The hypothesis is further refined into a prediction of what we may expect to happen in a certain situation. It should relate directly to the hypothesis.
Tim, like many others, was interested to see if carabiners were damaged by being dropped. The hypothesis stated that “carabiners should be retired if dropped from above waist height”. While this is quite a broad statement, he made the prediction that “carabiners that have been dropped from waist height (1m) and above (15m) will function to the 22kN minimum failure load (Black Diamond) and will not differ from carabiners which have not been dropped.” Tim took care to be specific in his predictions, and to include a control to which he could compare his results. Notice that Tim’s prediction aims to refute the hypothesis. This is known as a null hypothesis and it is important to note that when a null hypothesis is refuted, this does not automatically mean that the alternative hypothesis should be accepted.

Image credit: Tim Hill
We then move on to testing to see if the real world behaves as predicted. A hypothesis is not proven true by a test, but simply supported or refuted in that scenario. If many sound tests confirm the prediction, confidence in the hypothesis increases or, in Tim’s case, confidence in the null hypothesis decreases.
Tim’s tests were constructed as follows. He purchased 18 new non-locking aluminium carabiners and kept six undamaged as the control group. He dropped six carabiners from a height of 1m onto a hard surface. To the remaining six he attaching a piece of tape to the crotch to ensure they landed on the basket and they were dropped 15m onto a hard surface. He pulled each of these carabiners to destruction, recording the force at breaking point. In effect, trying to keep all other variables consistent, he altered an independent variable (the dropped distance of the carabiners) and attempted to find any correlation with a supposed dependent variable (the measured the force at breaking point) .
So, what makes a sound test? Tests that are valid, accurate, and reliable are more convincing that those that are not.
A valid test ensures that the results clearly relate to the question being asked. All external factors that could affect results should be kept consistent. Tim made efforts to manage other variables that may influence his results. He used all new carabiners, ensured controlled dropping distances, and tried to control how the carabiner landed.
An accurate test ensures that the dependent variable is being measured with appropriate resolution and accuracy. In this case, the force on the carabiners was measured using RopeLab’s 5t, 2,000Hz load cell which is entirely appropriate for this application.
A reliable test ensures that the test achieves consistent results. Repetition usually increases reliability and Tim included 6 repetitions in his test. The more times similar results are achieved, the more confidence we have in the results. RopeLab’s similar experiment is published as a members report here.
Test results may then need to undergo statistical analysis to draw conclusions. It is important to note that an apparent statistical correlation between variables does not necessarily prove causation. Once we consider the results we may reconsider our hypothesis, redesign a new prediction, and test to refine our understanding.
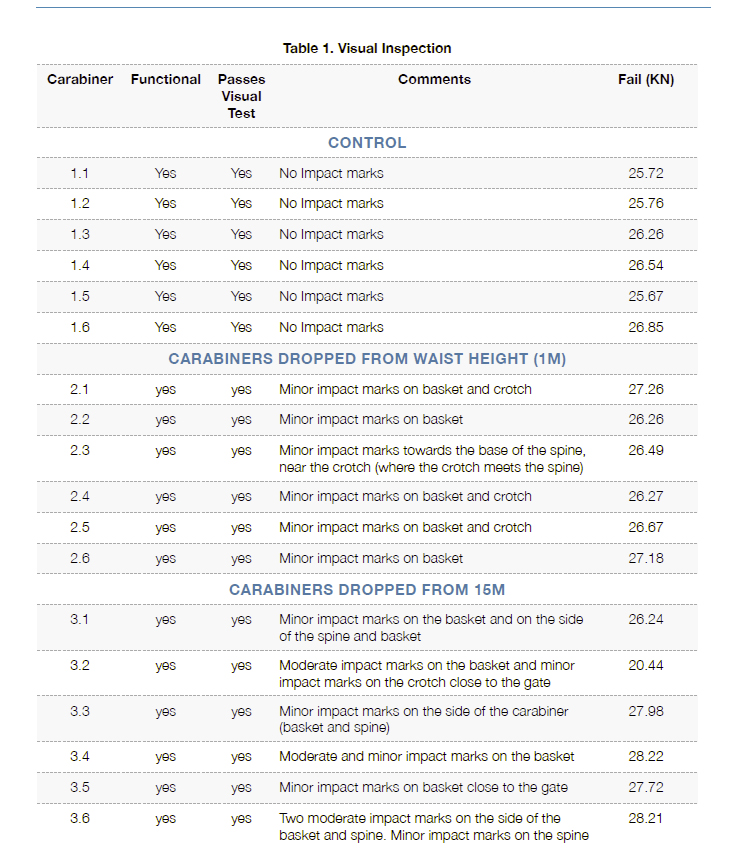
Tim’s test results largely confirmed his prediction. 17 carabiners broke at above 22kN and there was no statistical difference between the results from the 3 groups. However, Tim had one interesting result. He found 1 carabiner that had been dropped 15m broke below 22kN. Upon inspecting the broken carabiner he noted a significant impact scar with a depth of 0.2mm (or 2% of the overall thickness of the carabiner), and hypothesises that the location of the scar and its depth may have influenced the strength of the carabiner. He makes the recommendation that impact scars could be measured prior to breakage in future tests. This is certainly an interesting consideration in this issue and one that is worth exploring further.

Image credit: Tim Hill
Tim conducted a sound scientific experiment and we thank him for sharing his results with us. Each set of results adds to our understanding of complex issues. It is often the way that in the process of asking one question, many others arise. The scientific process is a cycle continually refining our understandings and this experiment shows beautifully the cycle of exploring, questioning, testing, understanding, sharing and back to the start all over again.
© RopeLab 2015
Related Posts




About The Author
Richard Delaney
Richard Delaney has worked professionally with ropes since 1992 as a multi-pitch rock-climbing instructor, technical rescue instructor and rope access technician. Understanding and teaching the Physics of Rigging is a core passion of Richard’s, one based on his experience, and his prior professional life as a qualified engineer.
Add a Comment
You must be logged in to post a comment.
That’s an interesting result and will certainly cause me to pay closer attention to the condition of my hardware. I’m curious now to see how the location, depth, profile and direction of scratches affects the breaking strain.